Introduction
Many people first hearing about vibe coding may interpret it as “creating software based on intuition without writing code.” This understanding can lead teams astray: either they become overly excited and treat it as a tool to replace programmers, or they outright reject it as just another AI marketing term. A more practical view is that vibe coding is shifting programmers’ focus from writing code line by line to describing intentions, breaking down tasks, reviewing results, and controlling risks. This article aims to help you assess how vibe coding has evolved over the past few years, how it should be used in the next three years, what tasks are suitable for it, and which tasks should be approached with caution.
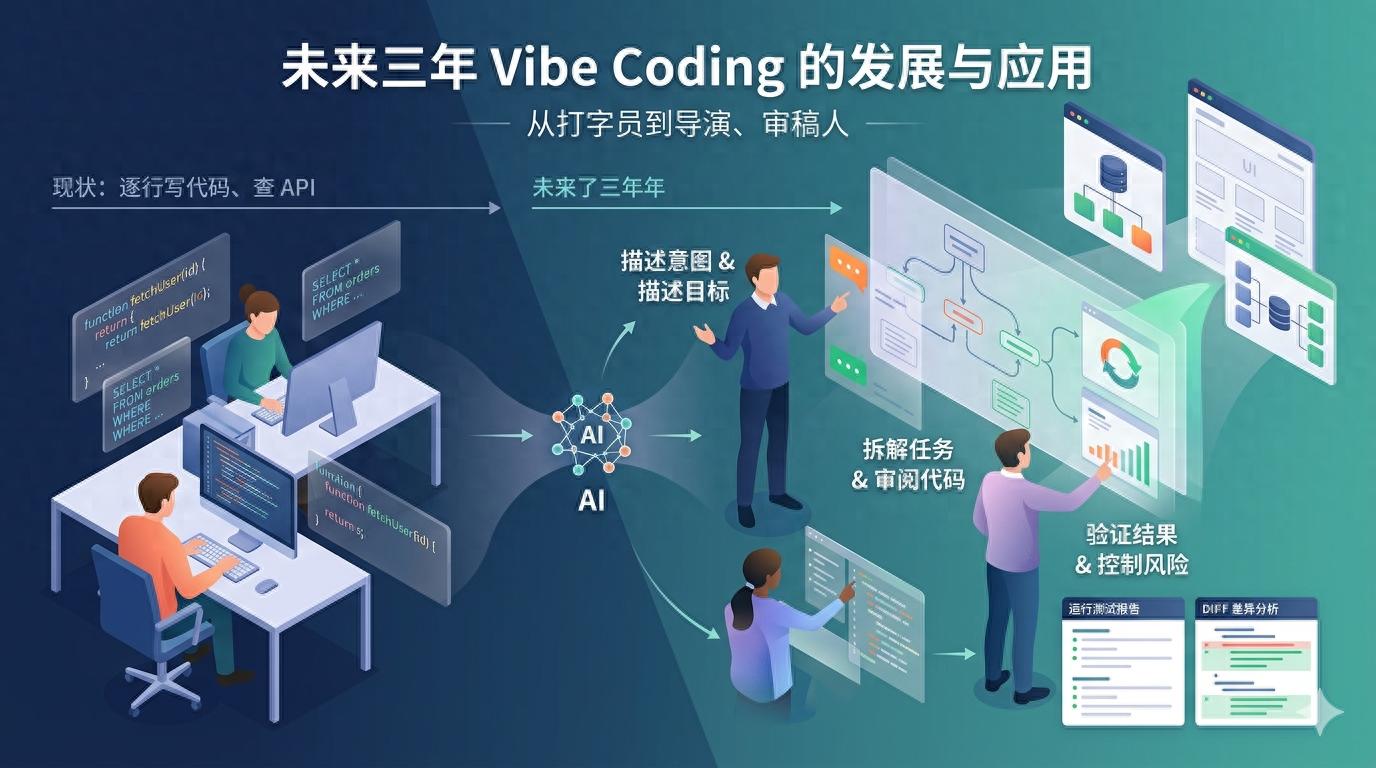
Not a Sudden Emergence
If you only look at the terminology that emerged around 2025, vibe coding may seem like a new concept. However, from the perspective of actual workflows, it is not a sudden appearance but rather the result of the evolution of code intelligence reaching a critical point.
The first stage was code completion. Early tools primarily solved the problem of “typing fewer characters”: suggesting variable names, function names, and template code based on context. This improved input efficiency, but developers still had to design structures, understand APIs, and locate bugs themselves. These tools were like a smarter input method.
The second stage was conversational programming. Large models began to explain segments of code, generate functions, modify SQL queries, and write unit tests. The change in this stage was that developers could express “what they wanted” in natural language and then integrate the results back into their projects. However, this was still fragmentary; true context, dependencies, build processes, and testing feedback still required human integration.
The third stage involved contextual collaboration within IDEs. Tools like Cursor, Claude Code, and GitHub Copilot Chat integrated models into the codebase environment. They no longer just looked at a pasted segment of code but could read files, check calls, run tests, and modify multiple files. This step was crucial because the real challenges programmers face when writing code often lie not in “writing a specific function” but in “modifying things within an existing system.”
The term vibe coding truly gained popularity because the fourth stage became usable: developers no longer had to start from every implementation detail but could first describe their goals, allowing AI to generate, modify, and validate, with humans deciding whether to accept the results. In other words, the human role shifted from “typist” to “director, reviewer, and risk manager.”
Why It Has Gained Popularity in Recent Years
A technology concept suddenly gaining traction typically results from several conditions maturing simultaneously.
The first condition is that model capabilities have surpassed a usable threshold. Previously, when AI was tasked with writing code, common issues included syntax errors that could run but were unusable in larger projects. Now, models have significantly improved in understanding cross-file contexts, error correction, and utilizing testing feedback, saving considerable time in scenarios like scripting, frontend pages, interface glue layers, CRUD operations, test completion, and documentation generation.
The second condition is that the toolchain has closed the loop. Merely being conversational is insufficient; true value comes from the ability to read repositories, modify files, run commands, check errors, and continue fixing. Development tasks inherently involve a feedback loop: write a bit, run it, correct errors. AI must enter this loop to transition from a “Q&A tool” to a “development collaborator.”
The third condition is that software demands have become fragmented. Many teams face not building a large system from scratch daily but modifying forms, connecting interfaces, completing scripts, changing styles, writing backend pages, migrating configurations, and creating internal tools. These tasks are valuable but highly repetitive, contextually dispersed, and costly in terms of communication. Vibe coding perfectly addresses these types of work: requirements can be expressed in natural language, results can be quickly validated, and the costs of failure are relatively controllable.
Thus, its popularity is not because “programmers no longer need to write code” but because many software development tasks were already not worth completing manually from scratch.
Common Misjudgments in the Development History
Many teams evaluating vibe coding make a mistake: they only look at the speed of code generation without considering the cost of receiving that code.
For example, if one person uses AI to generate a page in ten minutes, it seems efficient. However, if the styles do not conform to the existing component system, state management bypasses team agreements, and error handling and permission checks are omitted, others will spend more time cleaning up when they take over. What appears to be “fast” actually shifts costs to the review, integration, and maintenance stages.
Another misjudgment is attempting large-scale refactoring with AI. It might change several files at once and still pass some tests. But if developers lack sufficient context to understand the intent behind each change, this “seemingly complete” result can be dangerous. Problems may not immediately trigger errors but could surface in boundary conditions, permission paths, or historical data compatibility.
Additionally, some mistakenly view vibe coding as a low-barrier entrepreneurial tool. While it does lower the barrier for prototyping, a product manager, designer, or independent developer can quickly create a demonstrable version, but transitioning from a prototype to a maintainable product involves deployment, data security, permissions, payment, logging, monitoring, backups, and user support. These elements do not automatically disappear just because code generation is faster.
Therefore, the history of vibe coding is not about “AI going from not being able to write code to being able to write code” but rather “AI gradually entering the software delivery chain, while humans still bear the responsibility for engineering judgment.” Those who overlook the latter half of this statement are likely to encounter pitfalls.
Tasks Most Likely to Change in the Next Three Years
In the next three years, vibe coding will stabilize first in tasks that are clearly defined, have timely feedback, and low verification costs.
The first category is prototypes and internal tools. For example, creating an operational backend, data viewing page, batch processing script, or form flow page. These tasks often get stuck in scheduling because they are important but not core. Now, AI can quickly generate usable versions, which developers can then enhance with permissions, handle exceptions, and integrate into existing systems. The benefits here are direct: it does not replace core engineering but reduces the occupation of low-leverage tasks.
The second category is local modifications within existing codebases. For instance, adding a field to an interface, completing a set of tests, migrating a component’s writing style, renaming a section, or consolidating repeated logic into a single function. AI is becoming increasingly adept at these tasks because the goals are clear, the impact can be controlled, and they can easily be checked with tests and diffs.
The third category involves knowledge-intensive but repetitive engineering assistance. Examples include explaining unfamiliar modules, generating interface documentation, locating potential causes based on error logs, organizing PR changes into release notes, and converting test failure results into troubleshooting checklists. While these may not directly produce business code, they can reduce developers’ context-switching costs.
The fourth category is testing and validation. In the coming years, AI will not only write code but will also increasingly participate in “proving that a piece of code is reliable.” It will generate test cases based on changes, supplement boundary conditions, and propose fixes after failures. Truly mature teams will not just ask, “Can AI write?” but will be more concerned with “How do we validate after AI writes?”
Parts That Will Not Change Quickly
However, some aspects should not be overestimated.
Complex business modeling will not be quickly replaced by vibe coding. Issues like billing rules, risk control strategies, supply chain fulfillment, compliance in medical finance, and multi-person collaboration permissions are challenging not because of the code but due to business constraints, historical baggage, and boundaries of responsibility. AI can help you write implementations but will struggle to decide on the rules themselves.
Large system architecture will also not improve automatically due to a single prompt. Architectural decisions involve team capabilities, deployment environments, cost budgets, fault recovery, and future evolution. If these constraints are not included in the input, AI can easily propose “seemingly standard” solutions: microservices, queues, caching, layering, and monitoring may all be present, but they may not suit the current team.
Security and compliance should not be fully entrusted to AI. Especially in areas like authentication, data permissions, key handling, payment, and user privacy, human oversight is essential. AI-generated code may be syntactically correct but can still introduce issues like directly concatenating user inputs into queries, exposing sensitive logs, or misplacing permission checks.
Thus, the reality in the next three years is likely not that “AI programmers will replace human programmers” but rather that “programmers who know how to use AI will have a significantly larger delivery radius; those who cannot validate AI results will generate more technical debt.”
How Teams Should Use It Now
If you are an individual developer, the best initial use of vibe coding is in low-risk, high-repetition tasks. For example, writing scripts, creating initial drafts of pages, completing tests, organizing documentation, or explaining unfamiliar code. Avoid letting it rewrite core modules right away. First, establish a habit: every time you let AI modify code, break the task down into smaller parts and have it explain which files were changed, why they were changed, and how to validate them.
If you are a technical lead, it is more important to establish usage boundaries rather than prohibit everyone from using it. You can categorize tasks into three tiers.
The first tier includes tasks that can be directly used: documentation, test samples, scripts, small pages, non-core CRUD operations, and code explanations. These tasks encourage usage but require retaining readable diffs and validation commands.
The second tier consists of tasks that require strong manual review: cross-module modifications, data migrations, permission logic, performance-related changes, and public component renovations. AI can assist with these tasks, but it should not make large changes that are directly merged.
The third tier includes tasks that should temporarily not be led by AI: core architectural refactoring, security boundary design, complex business rule definitions, and online incident handling decisions. Here, AI can help organize materials and compare plans, but ultimate judgment must be made by someone familiar with the system.
At the same time, teams should elevate “writing good prompts” to “writing clear task descriptions.” A good vibe coding request should include at least four components: what the goal is, what cannot be broken, how to validate it, and where to limit the changes. For example, rather than just writing “optimize this interface,” specify “reduce the repeated database access for this query without changing the response structure, prioritizing modifications in the service layer, and running existing interface tests upon completion.”
The Real Barrier Will Shift from Writing Code to Validating Code
In the next three years, the core competitiveness of programmers will not disappear but will shift positions.
In the past, a junior developer spent a lot of time checking syntax, piecing together APIs, copying templates, and fixing minor bugs. AI will significantly compress this time. Meanwhile, code reviews, clarifying requirements, boundary judgments, fault localization, and system understanding will become more important.
This is not necessarily bad for newcomers, but the learning path will change. Previously, one could accumulate experience by gradually writing many small features; now, if one relies too early on AI, they might produce functionality without understanding why it was written that way or where the problems lie. Therefore, when newcomers use vibe coding, it is best to enforce two practices: have AI explain key changes and manually modify a small part of the code. Do not just accept changes blindly.
For experienced developers, the opportunity lies in amplifying their judgment. You can have AI draft implementations, outline troubleshooting paths, supplement tests, and organize migration steps, but you must set boundaries and acceptance criteria. The relationship between experienced developers and AI should not be about “who writes code for whom” but rather “who can more quickly push problems to a verifiable state.”
This is also the most practical value of vibe coding: it does not eliminate your thinking but shifts it from syntax and template levels to task design and result acceptance levels.
Three Pitfalls to Avoid Early
The first pitfall is throwing vague requirements directly at AI. The vaguer the requirements, the more AI tends to fill in the gaps. It may provide a complete solution, but many assumptions may not have been confirmed. The solution is not to write longer prompts but to list constraints: where the data comes from, who the users are, what to do in case of failure, and which existing behaviors cannot change.
The second pitfall is making too many changes at once. AI excels at continuous output, but humans struggle to review large diffs. A more stable approach is to break tasks into smaller steps: first read the code to provide a plan, then modify one module, run tests, and continue. This way, even if the direction is wrong, you can stop earlier.
The third pitfall is only verifying that the code “runs” without checking if it “meets expectations.” Many AI-generated codes may compile correctly but behave incorrectly in business logic. During acceptance, at least three aspects should be checked: normal paths, boundary inputs, and failure paths. If it is frontend, open the page and click through; if it is backend, at least supplement a set of tests or request samples that cover core branches.
These three pitfalls share the same principle: vibe coding lowers the cost of generation, not the cost of responsibility. Once code is in the repository and issues arise online, users will not care whether it was written by a human or AI.
A More Realistic Conclusion
In the next three years, vibe coding will transition from a “novel plaything” to one of the default development methods for many teams. It will not turn software engineering into a chat game, nor will it instantly make everyone a full-stack engineer. Instead, it is more likely to bring about a simple yet significant change: the same people can complete clearly defined tasks faster; the same tasks will rely more on clear descriptions and strict acceptance.
If you want to start now, there is no need to chase every new tool. Begin with a low-risk scenario, such as completing tests, writing internal scripts, or modifying a non-core page, and establish your small process: describe the goal, limit the scope, generate changes, run validations, and manually review diffs. Once this process runs smoothly, gradually expand to more complex work.
The focus of vibe coding is not on “writing code based on intuition” but on “expressing intentions in a more natural way and managing results through engineering methods.” Those who can achieve both will truly reap efficiency benefits in the coming three years.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.